2023 - Feb - 04
implementing GRU network
The idea is to develop a simple GRU network. And construct the agent. As for the basic implementation a single GRU cell network was used in Actor Critic.
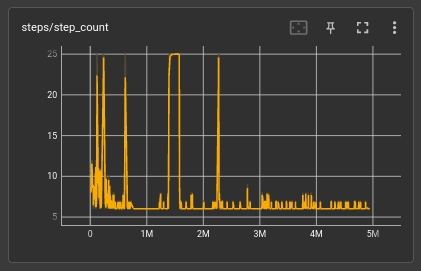
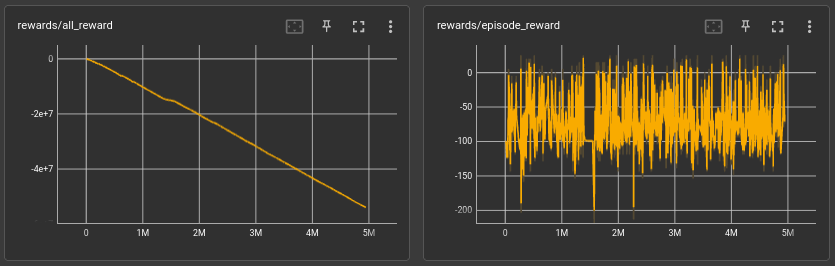
It has been observed through the use of the language model that the step count has stabilized, however, a deeper analysis of the results highlights that the model has been trained to reach the final state where it will receive a reward of 25. This focus on the final reward has led to a slight improvement in the performance of high-performing players, but it has also caused an increase in the variability of the reward plot.
The use of reward functions in reinforcement learning is critical in shaping the behavior of the model. A reward function can be defined as a scalar value that is assigned to the model for a specific state or action, with the objective of maximizing the total reward over time. In this particular language model, the reward function was designed to award 25 points for reaching the final state.
However, this approach has had some unintended consequences. The focus on the final reward has resulted in a reduced diversity of the model's behavior, as indicated by the increased variability of the reward plot. This reduced diversity could potentially impact the overall performance of the model, especially when introduced to other players.
implementing on LSTMs
Notes
yet to be updated since the last LSTM model outputs were not accurate at all need to refer the problem a bit