Using only the GRU layers
thinking process
I started from the beginning this time where I'll be going through the steps all over again but much faster. So this time I created 2 GRU cells with 32 hidden layers then feed it to the environment and saw that up to 4 players it was working partially without an sudden spikes here are there.
as for the input, A single observation was feed in to the network in the beginning and got a noisy plot. I assume that it fitted to a single value yet it can somehow move around the environment but still get a bad reward.
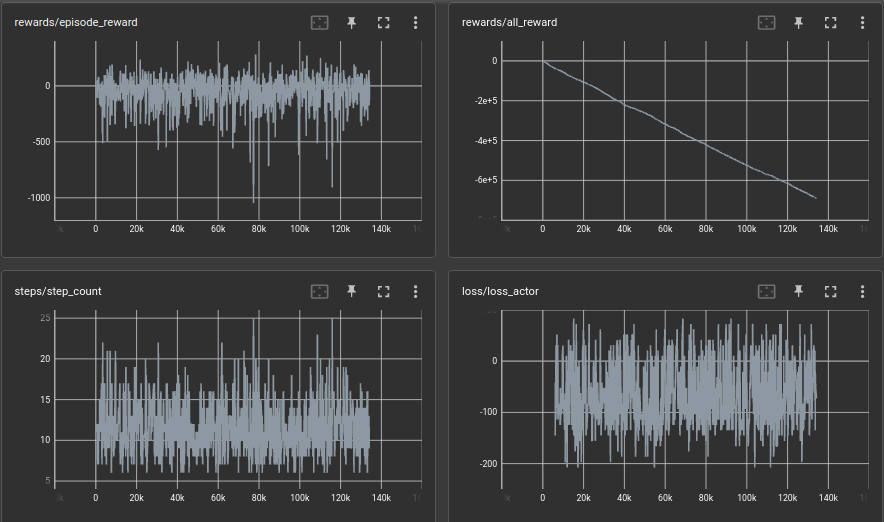
the next thing was input a whole sequence of data to the network, This gave me some promising result when considering all the other plots drawn so faw up to now. So in this position i experience that after adding the 4th player and running for some time the network explodes and goes it to complete randomness.
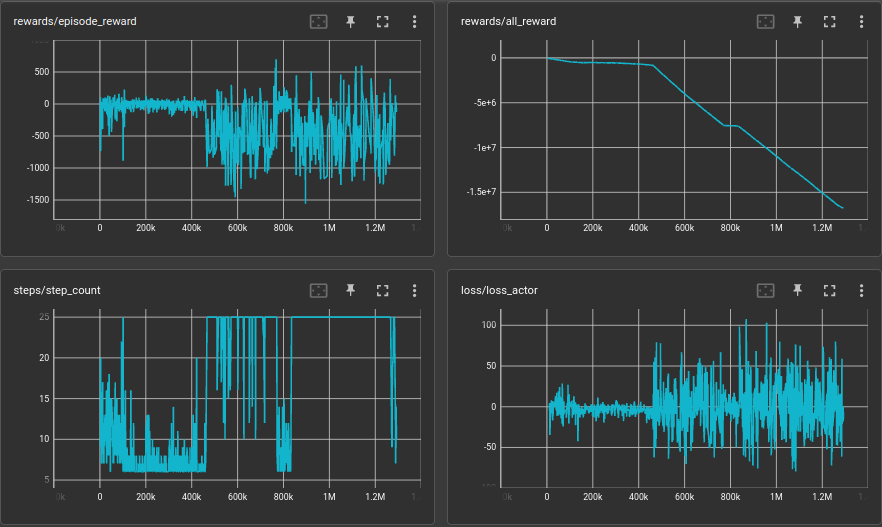
Here I saw that it can't learn because it didn't had enough parameters to learn the whole scenario. So the as for the next thing What i did was little bit hyper parameter tuning. Here I added num of layers in the GRU to 3. And as for the results the spikes have been minimized and the reward decay also has been reduced yet as for the overall reward process it goes down with a lower steep.
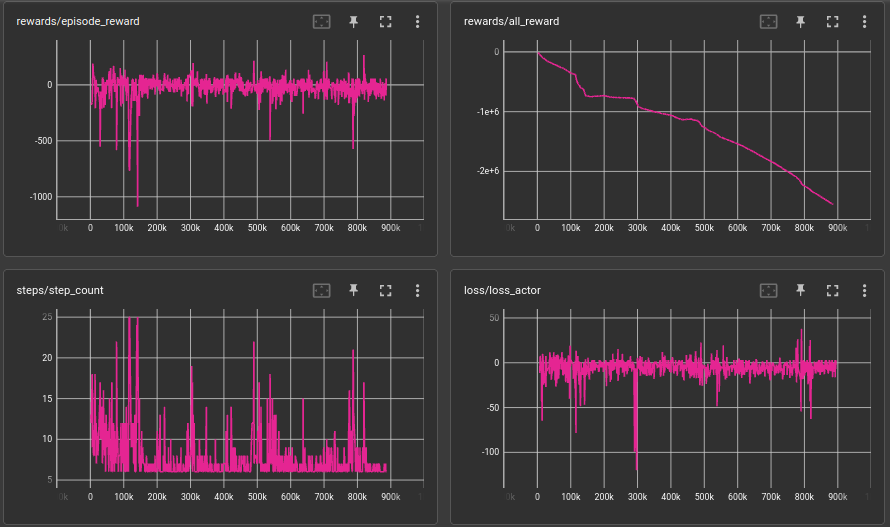
Notes
Stacking multiple Gated Recurrent Unit (GRU) layers can be beneficial for a few reasons:
-
Increased model capacity: By stacking multiple GRU layers, the model can learn more complex representations of the input data. This allows the model to better capture the underlying patterns in the data and make more accurate predictions.
-
Improved Gradient Propagation: GRUs have gating mechanisms that control the flow of information through the network. Stacking multiple GRU layers can help maintain this flow of information through the network, allowing gradients to propagate more effectively during backpropagation.
-
Deeper Representations: Stacking multiple GRU layers can provide deeper representations of the input data. This can be useful for more complex tasks that require higher-level abstractions of the data.
-
Regularization: By adding more layers to the model, you can reduce overfitting by adding more degrees of freedom to the model.
However, it's important to keep in mind that stacking too many GRU layers can lead to overfitting and longer training times. It's generally a good idea to experiment with different numbers of layers and find the best number for your specific task and dataset.